Name:Lan Vu
Date:12/5/2007
Course ID: CSC 5682
Semester:Fall 2007
OFFLINE HANDWRITING CHARACTER RECOGNITION
INTRODUCTION
For the first problem, some image processing algorithms are introduced. For
the second one, I choose the way of using neural network.
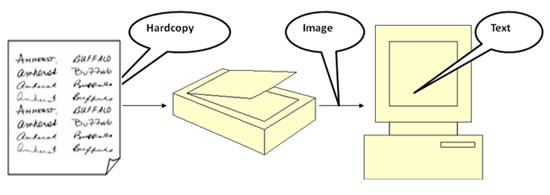
What is Offline Handwriting Character Recognition (OHCR)
System?
OHCR
is a method of converting visually readable characters into computer
readable characters. OHCR
programs are used with scanners to enter text into the computer from a
hardcopy version. We need OHCR because, even though we can read characters,
computers can’t. They use binary codes (ASCII) to represent characters. When
a document is scanned, the scanner provides us the image of the document (is
can be color image or binary image). OHCR applications will convert the
image to text. Then a word processing program can correct the mistake.
The Processes of Handwriting Character Recognition

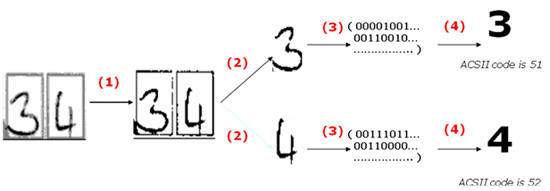
My
system isn’t a specific application in any field. Instead, it provides a
tool to create a recognition engine for using in other recognition
application. In this system, I
concern to only two of above processes: Preprocessing and Recognition.
PREPROCESSING
Preprocessing in my project is used to process raw patterns archived from
scanned images. After several preprocessing steps, the result is the
normalizing patterns. These patterns then can be used for training or
testing. There are several algorithms used by the application to convert the
raw image into proper image. The purpose of these transformation algorithms
is to provide the best possible input data for the recognition algorithms.
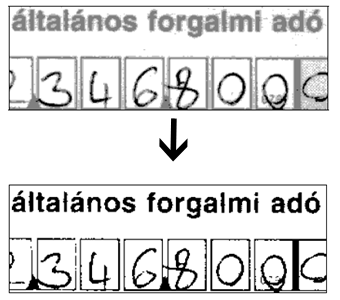
The problems of scanning image
Omitting the breaks of characters.
Filtering the background information that is part of the original
printed form and is not necessary or disturbs the recognition.
Checking and correcting skewed pictures (in case of both rotated and
slant pictures)
Normalizing characters
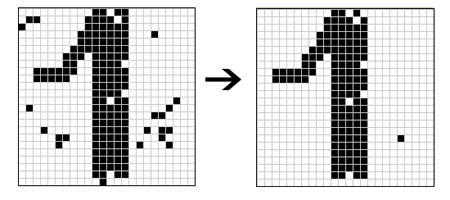
Straightening algorithm

Some
other normalized algorithms:
skeletonize, despace, deline…
RECOGNITION
Recognition model
Recognition can be occurred by different methods such as:
·
Neural Network (FNN, ANN, Combined NN...)
·
Hidden Markov model
·
Wavelet packet transform and Neuron-Fuzzy
·
Genetic-Algorithm
·
Adaptive Statistical Similarity (using Statistical tools such as Bayesian
and Gaussian)
·
Hybrid methods
Among these above methods, application of neural network is the most popular
one and I also choose this solution for my project. The following image
shows the model of my recognition network:
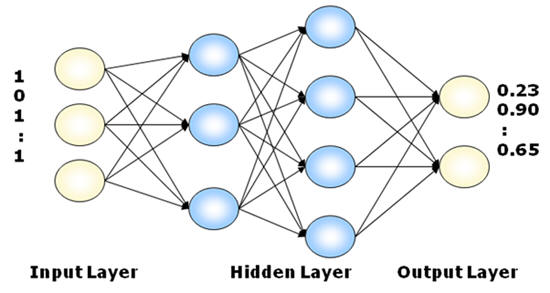
Input layer: this layer
receives input values which are a recognition pattern and trigger the
working process of the network. A recognition pattern here is a vector
representing the binary image of a character pattern. The default size
of recognition image is 24x24 so the vector size or the number of nodes
of input layers is 576 (=24*24).
Hidden layers: the number of
layers and the amount of nodes of each layer vary. The larger size of
these layers, the more memory ability of the network is; also the longer
training time and recognition time.
Output Layer: each output
node stands for a character. By default, my neural network allows to
distinguish 256 different characters, so the output has 256 nodes. There
is a mask for this output layer so that the user can choose not to use
all of 256 nodes. If just some of output nodes are used, the mask will
disable the other nodes. Among the output values, the node with largest
value will be chosen and the character accompanying with that node is
decided.
The training set
The
training set is a set of patterns and text codes (ASCII) standing for
characters. A pattern is the input of system and text code is the expected
output character.
Each
pattern is a binary image standing for character. This image results from a
raw image after being processed through some image processing algorithms
introduced in previous section. The default size of recognition image is
24x24. Because of learning by pattern, the recognition neural network has
576 input nodes (=24*24). Each node will receive value of a pixel.

In my
project, training set can be created by users or get from other resource
such as scanned patterns or NIST Database.
The training process
A new
recognition neural network is created with random weights of arcs. I don’t
set these values to 0 because I find that use random values, the training
time will be shorten.
Before
training, a training set is loaded and some of training information should
be set such as training times, min error, and momentum.
·
Training times: the time that network be trained. It’s not
depending on the size of training set.
·
Min error: The difference between output value and 1. It makes a
threshold to specify whether revise the weights of arcs of network or not.
·
Momentum: this parameter used to specify that the weights of arcs
of network are revised much or less after each learning time.
In the
training process, a pattern in the training set is converted to input vector
with 576 elements and the text code of that pattern is converted to expected
output vector. In this input vector, the value of elements standing for
black pixels is 1, otherwise the value is 0. The
Propation method of the neural
network will calculate an output vector depending on this input vector. Then
the output vector and the expected output vector are used in the
Backpropation method to revise
the weights of arcs in the neural network. Two parameters Min error and
Momentum are also used in this method to have a suitable learning way. The
learning process continues with next pattern until the training times is
reached.
TESTING RESULT
This
section will show you the effectiveness (%correct on the training set) of
the system after it has been trained and how well the system generalized to
data that was not in the training set.
For
testing purpose, I have created a digit recognition neural network which
allow to recognize ten digits (0, 1, 2, 3,… 9) with the structure:
Input layer:
576 nodes (image matrix 24x24)
Hidden layer 1:
256 nodes
Hidden
layer 2: 256 nodes
Output layer: 256 nodes (only
ten nodes standing for 10 digits are activated, the other nodes are masked
and not work).
The
training data is a part of NIST Database with 2000 digit patterns and the
testing data is also a part of NIST Database with other 2000 digit patterns.
The result of training and testing on this data set is shown in the below
table.
|
Training times |
Training times/pattern |
% Correct on Training data set |
% Correct on Testing data set |
|
0 |
0 |
12.6% |
8.9% |
|
2000 |
1 |
8.8% |
13.5% |
|
4000 |
2 |
22.9% |
13.5% |
|
8000 |
4 |
30.6% |
30.1% |
|
16000 |
8 |
37.7% |
36.3% |
|
32000 |
16 |
46.8% |
44.9% |
|
64000 |
32 |
61.4% |
58.3% |
|
… |
… |
… |
… |
You can
find in the source code package the file
TrainData.dat containing the
training data set the file
TestData.dat containing the testing data set. The
file DigitNet.net saves
information of the recognition neural network after training.
IMPLEMENT
The
computer simulation of Offline
Handwriting Character Recognition System is shown in below interface.
It is implemented in C++ language NET Framework 2.0. I choose C++ because of
it conveniences in working with memory for the image processing need.
Click here for full source code
of this program.
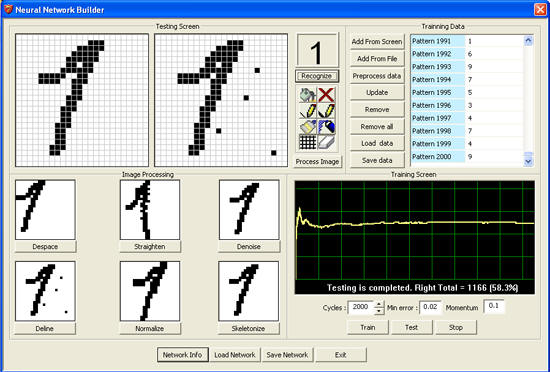
This
program consists of some main parts:
Steps to build a recognition neural network for a
specific purpose:
1.
Create
new neural network:
-
Click
button Network Info

-
Set
information of neural network that you want to create
-
Click OK
2.
Prepare
the training data set in the
Training data section
3.
Set
parameters in training screen section and start to train until the percent
of correction is accepted.
Some main class in source code:
|
#define
NUM_OF_LAYERS 50
class
CMLNet
{
public:
CMLNet(void);
~CMLNet(void);
enum
modeOutput {
OUT_ON = 0, OUT_OFF =
1};
CVecto
m_OutputMask;
CVecto m_errors;
CVecto m_deltas;
CVecto m_weights;
CVecto m_layers;
double
m_alpha;
double
m_bias;
void Initial(int
LayerCount,int* pNodes);
double FN(double
f) {return
double(1.0 / (1.0 + exp(-f)));}
double FD(double
f) {return
double(f *
(1.0 - f));}
// warning: will change a parameters of in_synapsys and
//outValss
vectors (size, capacity, doubles)
bool
Propagate(CVecto& inVals, CVecto& outVals);
bool
LearnPropagate(CVecto& inVals, CVecto& outVals); void BackPropagate(CVecto& outVals, CVecto&
idealVals,double N,double
M);
void
GetErrorWeight(CVecto& eVals,CVecto& wVal);
bool
Serialize(CArchive& ar);
void
RandomizeWeigths(double,
double);
bool
CheckConvergence(double);
void
SetOutputMask(CString strMask);
CString GetOutputMask(void);
double
GetErrorVal(void) {
return m_errors.GetTotalVal() ;};
void
SetAlpha(double alpha)
{m_alpha = alpha;}
void
SetBias(double bias)
{m_bias = bias
;}
int
GetInputCount() {
return (int)m_layers[0]
;}; int GetOutputCount()
{return (int)m_layers[m_layers.size()-1];};
int
GetLayerCount() {
return m_layers.size();}; int GetNodeCount(int nIndex)
{ return (int)m_layers[nIndex];};
bool Propagate()
{return Propagate(*m_inVal,
*m_outVal);}; bool LearnPropagate()
{return LearnPropagate(*m_inVal, *m_outVal);};
private:
//used only for mutil nets structure . Ex
: modular net
CVecto*
m_inVal
;
CVecto*
m_outVal;
double Delta (double N, double M,
double d,
double e , double y)
{ return
double( N * ((M * d) + ((1.0
- M) * e * y)));
}
}; //******************************************************
void
CMLNet::Initial(int
LayerCount,int* pNodes)
{
SetBias (1.0);
SetAlpha(1.0);
int numWeights = 0;
int numNeurons = 0;
int t = 0;
m_layers.resize(LayerCount);
for (int
i = 0; i < LayerCount ; ++i)
{
m_layers[i] = pNodes[i];
numWeights +=
(int)(t * m_layers[i]);
t
=
(int)m_layers[i] + 1
;
// add bias
}
for (int
l = 1 ; l <LayerCount; l++)
numNeurons += (int)m_layers[l];
TRY
{
m_weights.release();
m_deltas.release() ;
m_errors.release() ;
m_OutputMask.release();
m_weights.resize(numWeights);
m_deltas.resize(numWeights);
m_errors.resize(numNeurons);
m_OutputMask.resize((int)m_layers[m_layers.size()-1]);
}
CATCH_ALL(e)
{ e->ReportError();
e->Delete();
return;
}
END_CATCH_ALL
} //******************************************************
bool
CMLNet::Propagate(CVecto& inVals, CVecto& outVals)
{
int
w
= 0
;
int
max
= (int)m_layers[0] ;
double*
inVal = NULL
;
double*
outVal
= NULL
;
if (inVals.size() != (int)m_layers[0])
return
false;
//get num of mode in biggest layer
for (int
i = 1 ; i < m_layers.size(); i++ )
if ((int)m_layers[i]
> max) max = (int)m_layers[i];
inVal =
new
double[max];
outVal =
new
double[max];
//set input val
for (int
i = 0 ; i < inVals.size() ; i++ ) {
inVal[i] = inVals[i];
}
//Propagate
for (int
l = 1 ; l < m_layers.size(); l++ )
{
//for each out layer
for (int
i = 0; i < (int)m_layers[l] ; i++)
{
if (l==m_layers.size()-1 && m_OutputMask[i] ==
OUT_OFF)
{
outVal[i] = 0.0 ; }
else
{
double v = (m_weights[w] *
m_bias); w++;
//for each in layer for (int j = 0 ; j <(int)m_layers[l-1];
j++, w++ )
{
v = v + (inVal[j] * m_weights[w]);
} outVal[i] = FN(v);
// transfer Function
};
}
double* tmp
= inVal
;
inVal
= outVal;
outVal
= tmp ;
}
double* tmp
= inVal
;
inVal
= outVal;
outVal
= tmp ;
//set output val
for (int
i = 0 ; i < outVals.size() ; i++ )
outVals[i] = outVal[i];
delete [] inVal
;
delete [] outVal ;
return
true;
} //******************************************************
//return true if success
//outVals must be = NULL
bool
CMLNet::LearnPropagate(CVecto& inVals, CVecto& outVals)
{
int
w
= 0
;
int max
= 0
;
int numNode = 0
;
int
inPos = 0
;
int
outPos = (int)m_layers[0];
double*
inVal = NULL
;
//get num of node of layers
for (int
i = 0 ; i < m_layers.size(); i++)
{
numNode += (int)m_layers[i];
}
outVals.resize(numNode);
//set input val to the fisrt for (int i = 0 ; i < inVals.size() ; i++ )
{outVals[i] = inVals[i];}
//Propagate
for (int
l = 1 ; l < m_layers.size(); l++ )
{
//for each out layer
for (int
i = 0; i < (int)m_layers[l] ; i++) { if (l==m_layers.size()-1 && m_OutputMask[i] ==
OUT_OFF)
{ outVals[outPos
+ i] = 0.0;}
else
{
double v = (m_weights[w] *
m_bias); w++;
//for each in layer for (int j = 0 ; j < (int)m_layers[l-1];
j++, w++ )
{ v = v + outVals[inPos + j] *
m_weights[w];
}
outVals[outPos + i] = FN(v);
// transfer function
}
}
inPos =
outPos;
outPos += (int)m_layers[l];
}
return
true;
} //******************************************************
//back propagate
void
CMLNet::BackPropagate(CVecto& outVals, CVecto& idealVals,
double N,
double M)
{
int o
= outVals.size()
;
int e
= m_errors.size()
;
int w
= m_weights.size() ;
for ( int
l = m_layers.size()-1;
l>0; l-- )
{
int Nodes
= (int)m_layers[l];
int prevNodes
= (int)m_layers[l-1];
int aw
= w
;//pos
of matrix weight after layer
int ae
= e
;//used
when caculate non last layers
e
-= Nodes;//go
to fisrt node in this layer
o
-= Nodes
;
w
-=
(prevNodes+1)*Nodes;
int po
= o -
prevNodes
;
int nw
= w
;
for (int
i = 0 ; i<Nodes ; i++)
{
if (l==m_layers.size()-1)
{
if (m_OutputMask[i] ==
OUT_OFF ) continue; m_errors[e + i] = (idealVals[i] - outVals
[o+i])* FD(outVals[o+i]);
}
else
{ //compute error for each node
//of
non last layers
double
dsum = 0.0;
int
dw =
aw+i+1;
for (int
j=0 ; j<(int)m_layers[l+1]; j++) { dsum += (m_errors[ae + j] *
m_weights[dw]);
dw +=
(Nodes + 1); // skip bias
}
m_errors[e + i] = dsum * FD(outVals[o+i]);
//m_errors.SetVal(e + i,dsum );
}
if (m_errors[e+i] == 0)
continue;
// bias m_deltas[nw] = Delta(N, M, m_deltas[nw],
m_errors[e+i], m_bias);
m_weights[nw]= m_weights[nw] + m_deltas[nw];
nw++;
for(int
j = 0 ; j< prevNodes ;j++,nw++) { m_deltas[nw] = Delta(N, M, m_deltas[nw],
m_errors[e+i],outVals[po+j]);
m_weights[nw]= m_weights[nw]+ m_deltas[nw];
}
}
}
}
//******************************************************
void
CMLNet::GetErrorWeight(CVecto& eVals,CVecto& wVals)
{
int i,j,k;
eVals.resize((int)m_layers[1]);
wVals.resize((int)m_layers[0] * (int)m_layers[1]);
for (i = 0 ; i< eVals.size() ;i++)
eVals[i] = m_errors[i];
for (i=0,k=0 ; i< (int)(m_layers[1])
;i++)
{
for(j = 1 ; j<= (int)m_layers[0]
;j++)
wVals[k++] = m_weights[i*(int)m_layers[0]
+ j];
}
} //******************************************************
void
CMLNet::RandomizeWeigths(double lo,
double hi)
{
for (int
i = 0 ; i < m_weights.size(); i++)
{
m_weights[i] = lo + ((double)rand()
/ RAND_MAX) * (hi - lo);}
}
…. |
|
#define
HEADER_DATA_FILE_SIZE
20
#define
INPUT_NUM_POS
0
#define
OUTPUT_NUM_POS
1
#define
INPUT_SIZE_POS
2
#define
OUTPUT_SIZE_POS
3
#define
RECORD_NUM_POS
4
class
CRecognitionNetwork :public CMLNet
{
public:
int
m_InputRow
;
int
m_InputCol
;
int
m_OutputRow
;
int
m_OutputCol
;
enum
modeStatus {
modeBusy =0 , modeReady = 1};
char
m_Status;
bool
Get(unsigned,
unsigned z, CVecto& inVal,
CVecto& idealVal, CImageMatrix* Inputs, CImageMatrix*
Outputs);
bool
LoadDataFile(CString filename,CImageMatrix*
Inputs,CImageMatrix* Outputs);
bool
SaveDataFile(CString filename,CImageMatrix*
Inputs,CImageMatrix* Outputs);
void
SetInputOutput(int InputRow,int
InputCol,int OutputRow,int
OutputCol);
bool
Serialize(CArchive& ar);
CRecognitionNetwork(void);
~CRecognitionNetwork(void);
};
//---------------------------------------------------------------
CRecognitionNetwork::CRecognitionNetwork():CMLNet()
{m_Status
=
modeReady; }
//---------------------------------------------------------------CRecognitionNetwork::~CRecognitionNetwork(void){}
//---------------------------------------------------------------
void
CRecognitionNetwork::SetInputOutput(int
InputRow,int InputCol
,int OutputRow,int
OutputCol)
{
m_InputRow =
InputRow
;
m_InputCol =
InputCol
;
m_OutputRow =
OutputRow ;
m_OutputCol =
OutputCol ;
}
//-----------------------------------------------------------
bool
CRecognitionNetwork::LoadDataFile(CString filename,
CImageMatrix* Inputs,CImageMatrix* Outputs)
{
bool
nFlag = true;
CFile* file = new CFile();
//file couldn't read
if (!file->Open(filename, CFile::modeRead))
return
false;
//HEADER_DATA_FILE_SIZE = number of bytes
used to store header file
WORD* header
= new
WORD[HEADER_DATA_FILE_SIZE/2];
//incorrect file
if (file->Read(header,HEADER_DATA_FILE_SIZE)<
HEADER_DATA_FILE_SIZE )
{
file->Close();
return
false;
}
if (Inputs->GetMatrixSize() != (int)*(header
+ INPUT_NUM_POS ) ||
Outputs->GetMatrixSize() != (int)*(header
+ OUTPUT_NUM_POS) )
{
file->Close();
return
false;
}
int inRecSize
= (int)*(header +
INPUT_SIZE_POS) *
(int)*(header +
INPUT_NUM_POS );
int outRecSize
= (int)*(header +
OUTPUT_SIZE_POS)*
(int)*(header +
OUTPUT_NUM_POS);
int numRecords
= (int)*(header +
RECORD_NUM_POS);
BYTE* InputBuf =
new BYTE[inRecSize];
BYTE* OutputBuf=
new BYTE[outRecSize];
WORD val;
for(int
i=0 ; i< numRecords ;i++)
{
if ((file->Read(InputBuf,inRecSize))
< (UINT)inRecSize ||
(file->Read(&val,sizeof(WORD)))
< (UINT)sizeof(WORD) )
break;
memset(OutputBuf,0,outRecSize);
OutputBuf[val] = 1;//ON_OUTPUTVAL;
if (!Inputs->AddImageMatrix(InputBuf))
break;
if (!Outputs->AddImageMatrix(OutputBuf))
{
Inputs->RemoveAt(Inputs->GetCurrentImage());
break;
}
}
file->Close();
delete
file
;
delete [] header
;
delete [] InputBuf
;
delete [] OutputBuf
;
return
true;
}
//-----------------------------------------------------------------------------------
bool
CRecognitionNetwork::SaveDataFile(CString filename,
CImageMatrix* Inputs,CImageMatrix* Outputs)
{
CFile* file = new CFile();
//file couldn't read
if (!file->Open(filename, CFile::modeCreate
|
CFile::modeReadWrite|
CFile::shareExclusive))
return
false;
//HEADER_DATA_FILE_SIZE = number of bytes
used to store header file
WORD* header =
new WORD[HEADER_DATA_FILE_SIZE/2];
memset(header,0,HEADER_DATA_FILE_SIZE);
int inRecSize
= Inputs->GetMatrixSize()
;
int outRecSize
= Outputs->GetMatrixSize() ;
*(header + INPUT_NUM_POS
)
= (WORD)inRecSize;
*(header + OUTPUT_NUM_POS
)
= (WORD)outRecSize;
*(header + INPUT_SIZE_POS
)
= (WORD)1;
*(header + OUTPUT_SIZE_POS
)
= (WORD)1;
*(header + RECORD_NUM_POS
)
= (WORD)Inputs->GetImageCount();
file->Write(header,HEADER_DATA_FILE_SIZE);
WORD val;
BYTE *pOut;
for(int
i=0 ; i< Inputs->GetImageCount();i++)
{
Inputs->SetCurrentImage(i);
Outputs->SetCurrentImage(i);
val = 0;
pOut = Outputs->GetCurrentBuf();
for(int
j=0; j<outRecSize;j++){
if (*pOut++ == 1){//ON_OUTPUTVAL){
val = j;
break;
}
}
file->Write(Inputs->GetCurrentBuf(),inRecSize);
file->Write(&val,sizeof(WORD));
}
file->Close();
delete file;
delete [] header;
return
true;
}
//-----------------------------------------------------------------------------------
bool
CRecognitionNetwork::Get(unsigned,
unsigned z,
CVecto& inVal, CVecto& idealVal,
CImageMatrix* Inputs, CImageMatrix* Outputs)
{
static
int pRecPos
= 0 ;
//pointer to pos of Rec to read
if (Inputs->GetImageCount()
== 0 ||
Outputs->GetImageCount()== 0 )
return
false;
if (pRecPos >= Inputs->GetImageCount())
pRecPos = 0 ;
Inputs->SetCurrentImage(pRecPos)
;
Outputs->SetCurrentImage(pRecPos)
;
BYTE* InputBuf =
Inputs->GetCurrentBuf() ;
BYTE* OutputBuf = Outputs->GetCurrentBuf()
;
//at present m_pDataBuf have type if byte
, but it can change
//when the size of each input value or
out input value change
for (int
i = 0 ;i
< inVal.size() ; i++ )
{
inVal[i] = (InputBuf[i] == Inputs->PIXEL_ON)? 1 : 0;
}
for (int
id = 0; id < idealVal.size(); id++)
{
idealVal[id] = OutputBuf[id];
}
pRecPos++;
return
true;
}
…. |
CImageMatrix class:
manage the training data set. See the source code for more detail.
SOME APPLICATIONS
Address
readers
The
address reader in a postal mail sorter locates the destination address
block on a mail piece and reads the ZIP Code in this address block.
If
additional fields in the address block are read with high confidence the
system may generate a 9 digit ZIP Code for the piece. The resulting ZIP
Code is used to generate a bar code which is sprayed on the envelope.
The
Multiline Optical Character Reader (MLOCR) used by the United States
Postal Service
(USPS) The character classifier recognizes up to 400 fonts and the
system can process up to 45,000 mail pieces per hour.
Form
readers
A
form reading system needs to discriminate between pre-printed form
instructions and filled in data. The system is first trained with a
blank form. The system registers those areas on the form where the data
should be printed. During the form recognition phase, the system uses
the spatial information obtained from training to scan the regions that
should be filled with data.
Some
readers read hand-printed data as well as various machine written texts.
They can read data on a form without being confused with the form
instructions. Some systems can process forms at a rate of 5,800 forms
per hour.
Check
readers
A check
reader captures check images and recognizes courtesy amounts and account
information on the checks. Some readers also recognize the legal amount on
checks and use the information in both fields to cross-check the recognition
results. An operator can correct misclassified characters by
cross-validating the recognition results with the check image that appears
on a system console.
REFERENCE
Links on the Links page (Feedforward Backpropagation
Notes).
"An Introduction to Computing with Neural Nets" by R. P. Lippmann, IEEE ASSP Magazine, April 1987
Off-line Handwriting Recognition Using Artificial Neural Networks,
Andrew T. Wilson, University of Minnesota, Morris Morris, MN 56267
Hierarchical Character Recognition And Its Use In Handwrittenword/Phrase
Recognition
Handwritten Numeral Recognition: CARE - Computer Aided Recognition,
László Török1, Tibor Katona, József Vörös and Endre Jóföldi Kandó
Polytechnic of Technology, H-1431 Budapest, P.O.B. 112, Hungary
Implementation of an Algorithm for the Automatically Number Recognition
of Bus Numbers
by Murat Cetin Matriculation Number: 143201
Representation and Recognition of Handwritten Digits Using Deformable
Templates,
Anil K. Jain, Fellow, IEEE, and Douglas Zongker
A
Neural Network for Real-World Postal Address Recognition,
by Michael Blumenstein and Brijesh Verma, School of Information
Technology, Faculty of Engineering and Applied Science
Methods for Enhancing Neural Network Handwritten Character Recognition,
by M. D. Garris, R. A. Wilkinson, and C. L. Wilson, International Joint
Conference on Neural Networks, Volume I
Some
other internet resource.